





Why it’s important to address hard drive failure in the data center head on.
Storage technology is more sophisticated and durable than it’s ever been. But nothing lasts forever, and that includes hard drives. While the comparative durability of HDDs and SSDs depends on specific models and use cases, HDD is more fragile than solid state when it comes to bumps, jostles, and environmental factors.
Given this vulnerability, it’s important to address HDD failure in the data center proactively, whether you’re a storage architect or an IT asset manager. Knowing why hard drives fail, and how to manage failures, helps maintain data integrity and avoid waste.
Why Drives Fail
Before breaking down the main causes of failure, let’s marvel for a moment that HDDs don’t fail more often!
A modern hard disk drive is an extremely sophisticated instrument that puts the most intricate clockwork to shame. Drives today usually spin at somewhere between 5400-7200 rpm. That’s 90-120 revolutions per second.
Even more mind-boggling is the miniscule distance between the read/write head and the disk. This “flying height” is usually around 5-10 nanometers, but for extremely dense disk storage, the height must be less than five nanometers. For comparison, five nanometers is about twice the width of a strand of DNA!
Flying heights are so small that if you take a drive above 10,000 ft, the reduced air cushion might lead to a head crash. Careful when taking your disk drives to Cusco!
With so many moving parts, there are several ways a hard drive can fail.
The most common cause by far, at 70%, is damage to recording surfaces when drives get dropped, hit, or otherwise mishandled, according to research from DriveSavers. This includes plates cracking or shattering, as well as scratches incurred in “head crashes”, where the write head slams into the platter.
Second place, at 18%, are circuit board failures, usually caused by moisture or static. Finally, 11% of failures are due to “stiction”, where the armatures of the flying heads get stuck, sometimes due to lack of use.
Measuring Drive Failure
Nothing lays the groundwork for management like measurement, and there are several metrics available to track drive failure.
One common measure is Mean Time Between Failures (MTBF), which has the virtue of being precisely what it sounds like. Rather than waiting years to see how often drives fail in the interim, MTBF can be estimated via accelerated life testing, where a large group of drives is run at high temperatures for a set number of days.

Related Reading
While it’s important to know how reliable different models of drives are, it can also be helpful to know how to perform health checks on individual drives. HDDs collect “SMART attributes” about their internal functioning, and these attributes can be used to predict failure.
Another metric for drive failure is the “annualized failure rate”, or AFR. AFR is the % chance that a drive will fail within a year, calculated from the behavior of similar drives. AFR is usually only accurate for the first three years of a hard drive’s life.
Measuring failure rates isn’t an exact science, as AFR is difficult to determine, and a lot of variables can make or break an individual HDD. However, these metrics can provide an interesting window into general trends, such as how a hard drive’s reliability varies over its lifetime.
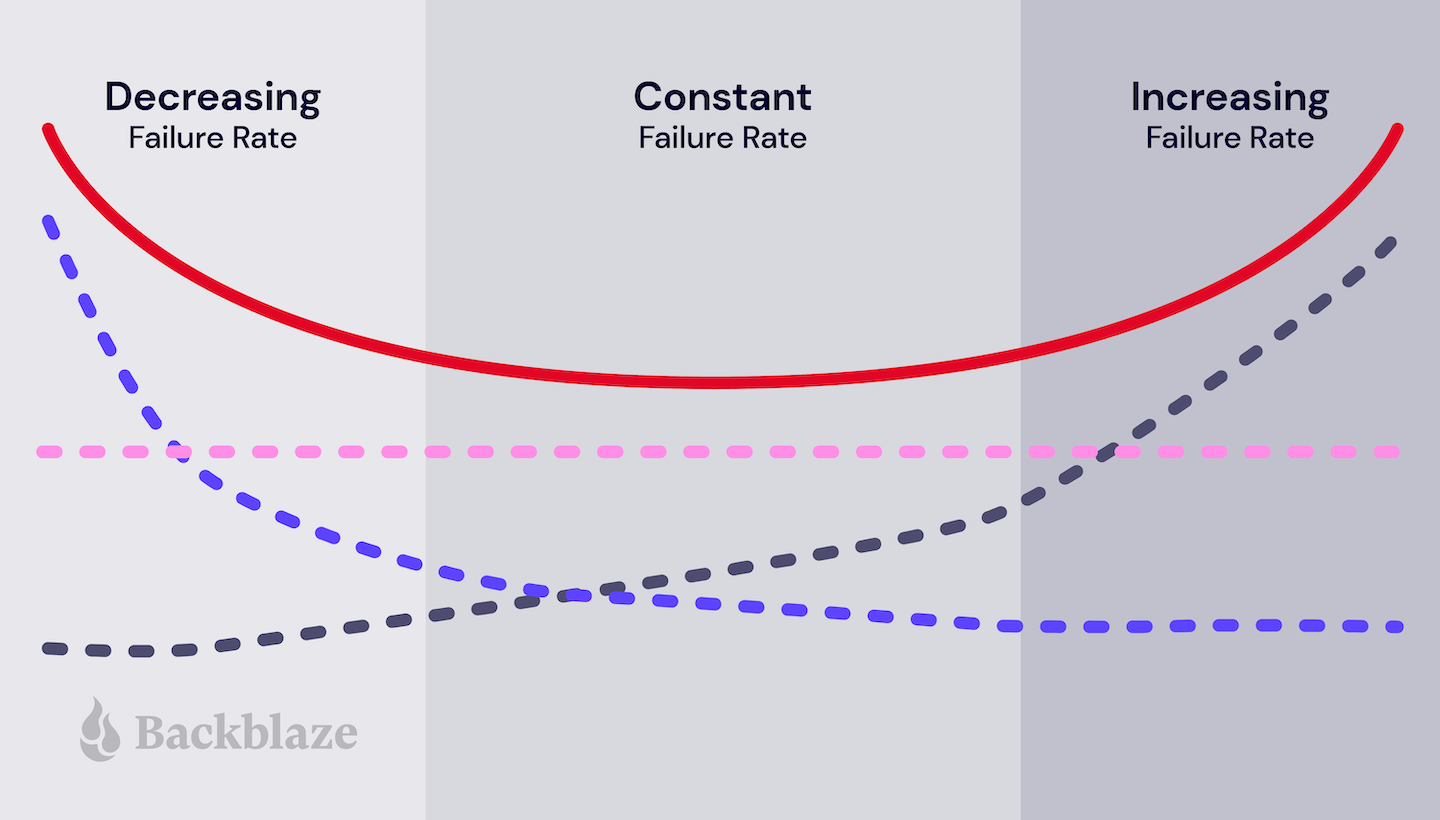
Hard Drive Failure Costs
It’s hard to determine the costs of HDD failure, which can vary widely depending on drive deployment within the data center environment.
This much is clear, however: the more drives you lose, the more replacements you’ll need, impacting both the environment and your wallet.
Don’t be too quick to junk failed drives. Even if they can’t be repaired, drives contain valuable metal components which can be recycled or resold.
Also, enterprise data centers must strictly maintain the integrity of stored data by ensuring sufficient redundancies and backups. In the event data isn’t properly backed up, reading data off of failed HDDs can be incredibly expensive, costing hundreds, or even thousands of dollars.
HDD Failure: Prevention and Management
When it comes to HDD failure, you can either take steps to prevent it or learn to live with it.
Preventative management is often hardware oriented, while living with a certain amount of drive failure requires the use of virtualization technologies and software tools. The best solutions tend to mix preventative measures with a robust system of backups and redundancies.
Of course, preventing failure isn’t as simple as purchasing drives with a reputation for reliability. AFR is a blunt tool, and drive turnover is often only a few years. Even experienced companies sometimes find that purchased drives fail more quickly than expected.
That said, the lion’s share of drive failures are due to environmental factors. Accordingly, the best way to maintain the physical integrity of your center’s hard drives is to look after them. For this, it’s wise to adopt a drive handling plan.
Related Reading
Certain HDDs are “ruggedized” to minimize malfunctions due to moisture, dust, extreme temperatures, and drops. However, these drives are expensive, and not a viable solution for data centers, though they form an integral part of edge data transfer services.
Drive handling plans clearly set out protocols that staff should follow when installing and working with hard drives. They can include physical protections such as strategically placed rubber mats to catch dropped drives, or static proof bags to minimize circuit board failures.

Finally, it’s important to keep the physical environment of the drives clean and at the proper temperature.
Living with Drive Failure
The preventative measures above are fairly common. However, some drives will still fail. Thankfully, this is hardly a new problem, and there’s a host of virtualization technologies which can prevent unintended data loss.
RAID
One of the most common virtualization technologies is RAID, or Redundant Array of Independent Disks. Developed in 1987, RAID does more than prevent data loss一it can also turbo charge the speed of your HDD operations.
The technology comes in several levels of increasing sophistication.
- RAID 0 stripes data across all drives, increasing speed but providing no redundancy or protection against loss.
- RAID 1 involves “mirroring”, redundantly copying data onto identical drives. This also offers increased read speeds, since you can read from multiple drives.
- RAID 10 uses data striping and mirroring, and lets you reconstruct data even if you lose half of your disks.
Mirroring is the most obvious way to create redundancy, but not the only way. “Parity” is a technique for adding checksums into data, allowing you to reconstruct a failed drive’s data from the sums (“parity data”) and the data on the remaining drives.
The specifics vary and can be quite technical, but here’s a simplified example of parity:
Suppose Drive 1 stores “001001” and Drive 2 stores “010101”. Then, putting “1” where bits agree, and “0” otherwise, we get “100011” for parity data, and store this in Disk 3.
If Disk 2 fails, then since you know what’s in Disk 1, and that Disk 3 tells you where Disk 1 agrees with Disk 2, you can reconstruct the contents of Disk 2. Voila!
RAID 5 and 6 distributes parity data across drives, and protects you from the loss of 1 or 2 drives respectively, while also offering increased speed.
Erasure Coding
RAID has its limitations, however. Firstly, it doesn’t provide any protection against human error or data corruption. High-level RAID is also quite difficult to manage and maintain. Finally, RAID can take a long time to reconstruct data lost in a drive failure.
How to get past these limitations? With the power of math, of course!
Like RAID 5 and 6, erasure coding involves reconstructing missing information via the use of parity data. But quite unlike RAID, it makes use of some more advanced mathematics, as encapsulated in the Reed-Solomon algorithm for error-correction.
Does erasure coding work? Just ask Microsoft, which uses erasure coding in the data centers which underlie its Azure storage service.
In a nutshell, erasure coding lets you use “parity blocks” to regrow missing data like a tree from a seed. While CPU intensive, this coding is scalable, configurable, and space-efficient.
The Future: Self-Healing Data Centers
There’s no shortage of virtualization technologies which can help maintain data integrity in the face of failed drives. However, many of these technologies, especially RAID, still require a certain amount of oversight and decision making, and can become unwieldy at scale.
What if that oversight could be automated?
Enter self-healing data centers. In a nutshell, the dream is for centers capable of automatically detecting data corruption and other errors, and reconstructing the data accordingly. Such data centers could operate on a large scale, ideally as large as a whole cloud. Self-healing drives are a natural place to start, as are innovations in drive failure prediction.

Imagine a data center that can deal with failed drives and corrupted data as easily as our brain handles failed neurons or synapses.
This is cutting-edge stuff, and such centers are still in their infancy. But the interest is there. Last year Calamu, a startup, received a total of $18.9 million in funding to develop multi-cloud self-healing technology, with a particular focus on cybersecurity.
Creating such centers will involve a lot of tech. One piece of the puzzle will be using machine learning to predict hard drive failure, something firms like Google and Seagate, as well as Backblaze, are actively working on.
These initiatives pave the way for interpretable machine learning techniques. Accurately predicting hard drive failure is great, but it’s even better if a program can give us insight into why drives are failing. One major step toward truly self-healing data centers involves having techniques which balance predictive performance and meaningful insights. Interpretable machine learning may eventually provide just such techniques.
Managing Hard Drive Failure
Drives fail, but your data center can still thrive.
Whether it’s a carefully implemented drive handling plan or judicious use of RAID, there are plenty of options for managing drive failure.
It may take some trial and error, but the payoffs are real. Managing hard drive failure does more than help you maintain data integrity and save money. It’s also a golden opportunity to use virtualization technologies to speed up your data retrieval operations. Plus, rethinking the life cycle of your hard drives is a golden opportunity to green your data center.
Managing hard drive failure effectively is a step toward sustainable renewal.
For expert assistance with your hard drive management in the data center, ask Horizon Technology to help.



